
Μια νέα ανάρτηση στο ιστολόγιο της Apple Machine Learning Research δείχνει πόσο βελτιώθηκε το πυρίτιο της Apple M5 σε σχέση με το M4 όταν πρόκειται για τη λειτουργία ενός τοπικού LLM. Εδώ είναι οι λεπτομέρειες.
Λίγο πλαίσιο
Πριν από μερικά χρόνια, η Apple κυκλοφόρησε το MLX, το οποίο η εταιρεία περιγράφει ως «ένα πλαίσιο συστοιχίας για αποτελεσματική και ευέλικτη μηχανική εκμάθηση σε πυρίτιο της Apple».
Στην πράξη, MLX είναι ένα πλαίσιο ανοιχτού κώδικα που βοηθά τους προγραμματιστές να δημιουργούν και να εκτελούν μοντέλα μηχανικής εκμάθησης εγγενώς στους υπολογιστές τους Apple silicon Mac, που υποστηρίζονται από API και διεπαφές που είναι γνωστές στον κόσμο της τεχνητής νοημοσύνης.
Εδώ είναι πάλι η Apple στο MLX:
Το MLX είναι ένα πλαίσιο συστοιχιών ανοιχτού κώδικα που είναι αποτελεσματικό, ευέλικτο και εξαιρετικά ρυθμισμένο για το πυρίτιο της Apple. Μπορείτε να χρησιμοποιήσετε το MLX για μια μεγάλη ποικιλία εφαρμογών που κυμαίνονται από αριθμητικές προσομοιώσεις και επιστημονικούς υπολογιστές έως μηχανική εκμάθηση. Το MLX διαθέτει ενσωματωμένη υποστήριξη για εκπαίδευση και εξαγωγή συμπερασμάτων νευρωνικών δικτύων, συμπεριλαμβανομένης της δημιουργίας κειμένου και εικόνων. Το MLX διευκολύνει τη δημιουργία κειμένου με ή με ακρίβεια μοντέλων μεγάλων γλωσσών σε συσκευές σιλικόνης Apple.
Το MLX εκμεταλλεύεται την ενοποιημένη αρχιτεκτονική μνήμης της Apple silicon. Οι λειτουργίες στο MLX μπορούν να εκτελεστούν είτε στη CPU είτε στη GPU χωρίς να χρειάζεται να μετακινήσετε τη μνήμη. Το API ακολουθεί πιστά το NumPy και είναι οικείο και ευέλικτο. Το MLX διαθέτει επίσης πακέτα νευρωνικών δικτύων και βελτιστοποιητών υψηλότερου επιπέδου μαζί με μετασχηματισμούς συναρτήσεων για αυτόματη διαφοροποίηση και βελτιστοποίηση γραφημάτων.
Ένα από τα πακέτα MLX που είναι διαθέσιμα σήμερα είναι το MLX LM, το οποίο προορίζεται για τη δημιουργία κειμένου και τη βελτίωση των μοντέλων γλώσσας σε υπολογιστές Apple silicon Mac.
Με το MLX LM, οι προγραμματιστές και οι χρήστες μπορούν να κατεβάσουν τα περισσότερα μοντέλα που είναι διαθέσιμα στο Αγκαλιασμένο πρόσωποκαι εκτελέστε τα τοπικά.
Αυτό το πλαίσιο υποστηρίζει ακόμη και την κβαντοποίηση, η οποία είναι μια μέθοδος συμπίεσης που επιτρέπει σε μεγάλα μοντέλα να εκτελούνται ενώ χρησιμοποιούν λιγότερη μνήμη. Αυτό οδηγεί σε ταχύτερη εξαγωγή συμπερασμάτων, που είναι βασικά το βήμα κατά το οποίο το μοντέλο παράγει μια απάντηση σε μια είσοδο ή μια προτροπή.
Μ5 έναντι Μ4
Σε αυτό ανάρτηση ιστολογίουη Apple παρουσιάζει τα κέρδη απόδοσης συμπερασμάτων του νέου τσιπ M5, χάρη στους νέους νευρωνικούς επιταχυντές GPU του τσιπ, τους οποίους η Apple λέει ότι «παρέχουν[s] αποκλειστικές λειτουργίες πολλαπλασιασμού μήτρας, οι οποίες είναι κρίσιμες για πολλούς φόρτους εργασίας μηχανικής εκμάθησης.»
Για να απεικονίσει τα κέρδη απόδοσης, η Apple συνέκρινε τον χρόνο που χρειάστηκαν πολλά ανοιχτά μοντέλα για να δημιουργήσουν το πρώτο διακριτικό μετά τη λήψη μιας προτροπής σε ένα M4 και ένα M5 MacBook Pro, χρησιμοποιώντας το MLX LM.
Ή, όπως το έθεσε η Apple:
Αξιολογούμε τα Qwen 1.7B και 8B, σε εγγενή ακρίβεια BF16, και 4-bit κβαντισμένα μοντέλα Qwen 8B και Qwen 14B. Επιπλέον, συγκρίνουμε δύο Mixture of Experts (MoE): Qwen 30B (ενεργές παράμετροι 3B, κβαντισμένες 4-bit) και GPT OSS 20B (με εγγενή ακρίβεια MXFP4). Η αξιολόγηση πραγματοποιείται με το mlx_lm.generate και αναφέρεται ως προς το χρόνο μέχρι την πρώτη δημιουργία διακριτικού (σε δευτερόλεπτα) και την ταχύτητα παραγωγής (σε όρους διακριτικού/ων). Σε όλα αυτά τα σημεία αναφοράς, το μέγεθος προτροπής είναι 4096. Η ταχύτητα δημιουργίας αξιολογήθηκε όταν δημιουργήθηκαν 128 επιπλέον διακριτικά.
Αυτά ήταν τα αποτελέσματα:
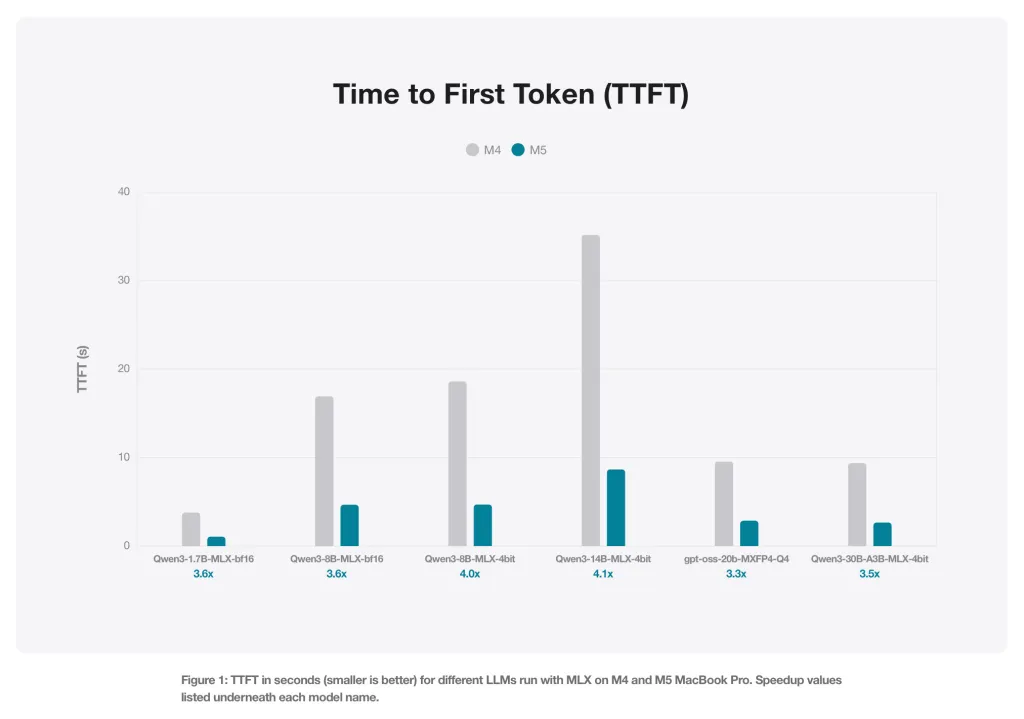
Μια σημαντική λεπτομέρεια εδώ είναι ότι το συμπέρασμα LLM ακολουθεί διαφορετικές προσεγγίσεις για τη δημιουργία του πρώτου διακριτικού, σε σύγκριση με το πώς λειτουργεί κάτω από την κουκούλα για να δημιουργήσει τα επόμενα διακριτικά. Με λίγα λόγια, το πρώτο συμπέρασμα διακριτικού είναι δεσμευμένο σε υπολογισμό, ενώ η επακόλουθη δημιουργία διακριτικών είναι δεσμευμένη στη μνήμη.
Αυτός είναι ο λόγος για τον οποίο η Apple αξιολόγησε επίσης την ταχύτητα παραγωγής για 128 επιπλέον μάρκες, όπως περιγράφεται παραπάνω. Και γενικά, το M5 παρουσίασε 19-27% ώθηση απόδοσης σε σύγκριση με το M4.
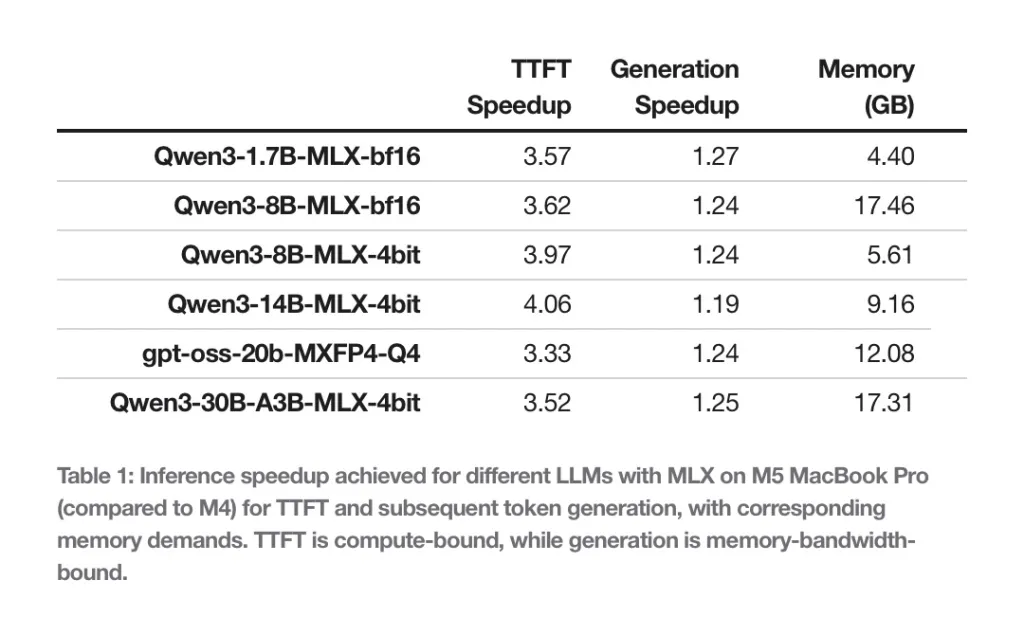
Εδώ είναι η Apple για αυτά τα αποτελέσματα:
Στις αρχιτεκτονικές που δοκιμάσαμε σε αυτήν την ανάρτηση, το M5 παρέχει 19-27% ενίσχυση απόδοσης σε σύγκριση με το M4, χάρη στο μεγαλύτερο εύρος ζώνης μνήμης (120 GB/s για το M4, 153 GB/s για το M5, το οποίο είναι 28% υψηλότερο). Όσον αφορά το αποτύπωμα μνήμης, το MacBook Pro 24 GB μπορεί εύκολα να κρατήσει 8B σε ακρίβεια BF16 ή 30B MoE 4-bit κβαντοποιημένο, διατηρώντας το φόρτο εργασίας εξαγωγής κάτω από 18 GB και για τις δύο αυτές αρχιτεκτονικές.
Η Apple συνέκρινε επίσης τη διαφορά απόδοσης για τη δημιουργία εικόνας και είπε ότι η M5 έκανε τη δουλειά περισσότερο από 3,8 φορές πιο γρήγορα από την M4.
Μπορείτε να διαβάσετε την πλήρη ανάρτηση ιστολογίου της Apple εδώκαι μπορείτε να μάθετε περισσότερα για το MLX εδώ.
Προσφορές αξεσουάρ στο Amazon
FTC: Χρησιμοποιούμε συνδέσμους θυγατρικών που κερδίζουν αυτόματα εισόδημα. Περισσότερο.
Via: 9to5mac.com












